MNIST es un conjunto de datos (dataset) de números escritos a mano y en esta guía entrenaremos un clasificador y lo evaluaremos.

Usaré Google Colab para esta guía, si no tienes configurado un entorno aún puedes hacerlo siguiendo este post!
Cargar el conjunto de datos
Tenemos diversas formas de cargar un conjunto de datos, estos están disponibles en datos tabulados (.csv), imágenes (.jpeg/.png), textos, etc…
En esta guía lo importaremos haciendo uso de tensorflow. Está disponible a través de la siguiente línea de código
from tensorflow.keras.datasets import mnistOk lo importé pero falta algo ¿Cómo accedemos a los datos?
Tenemos un método disponible:
mnist.load_data()Una vez ejecutado podemos entender que es lo que hizo el método, ha descargado mnist.npz y lo devuelve en formato tupla
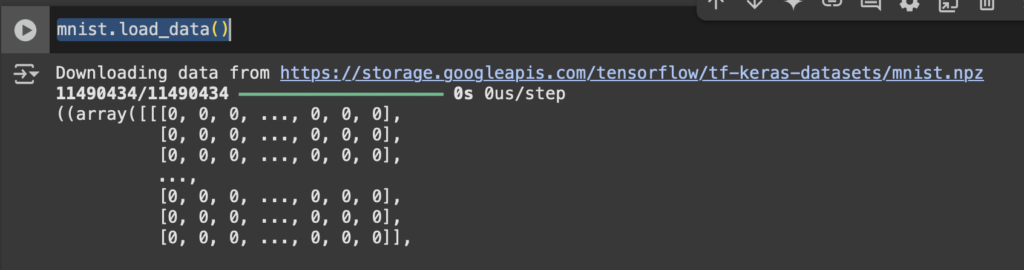
Vamos a acceder a estos valores, modificaremos el código a
(x_train, y_train), (x_test, y_test) = mnist.load_data()El dataset está compuesto por 2 tuplas, podemos entender esto como data de entrenamiento y data de validación.
Veamos el primer valor de x_train y el primer valor de y_train
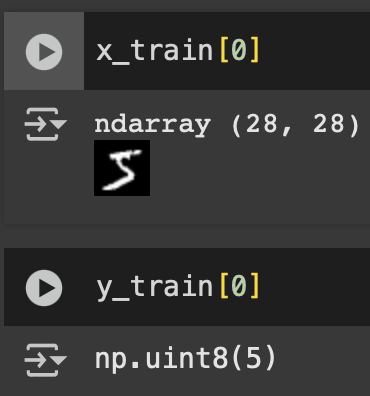
¿Qué valores tenemos ahora?
- x_train[0]: Un ndarray de tamaño 28×28
- y_train[0]: un uint8 de valor 5
Perfecto! están relacionados. Es nuestra data de entrenamiento que podemos entender como imagen y etiqueta.
Normalicemos nuestros valores
El proceso de normalización es parte esencial cuando trabajamos con clasificadores. ¿Por qué se normalizan los datos? Las redes neuronales aprenden mejor con datos en rangos pequeños porque evita valores grandes que podrían dificultar la convergencia del modelo.
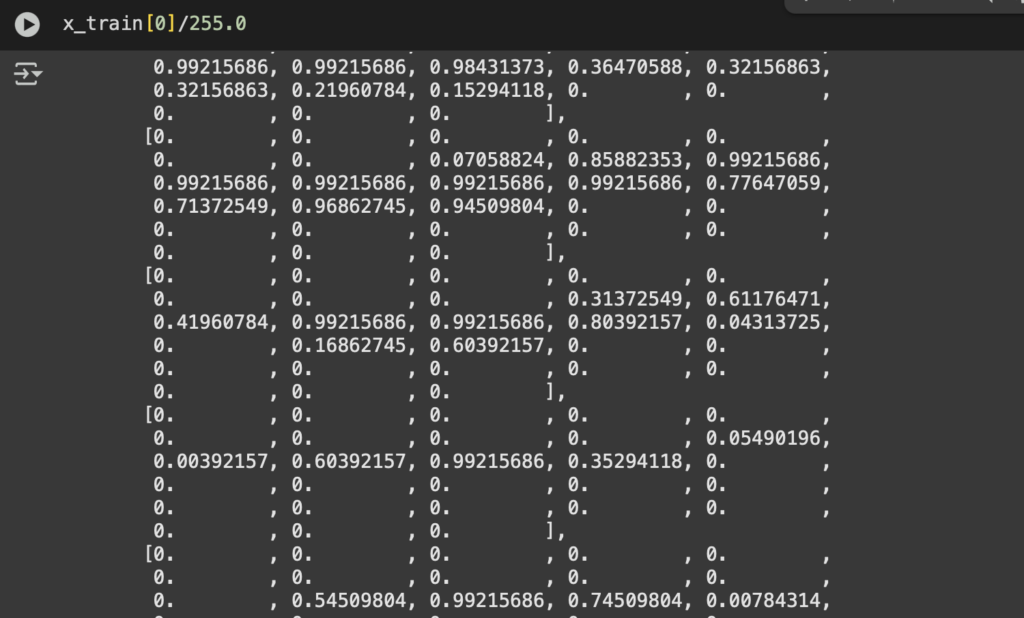
x_train, x_test = x_train / 255.0, x_test / 255.0¿Por qué dividimos por 255.0?
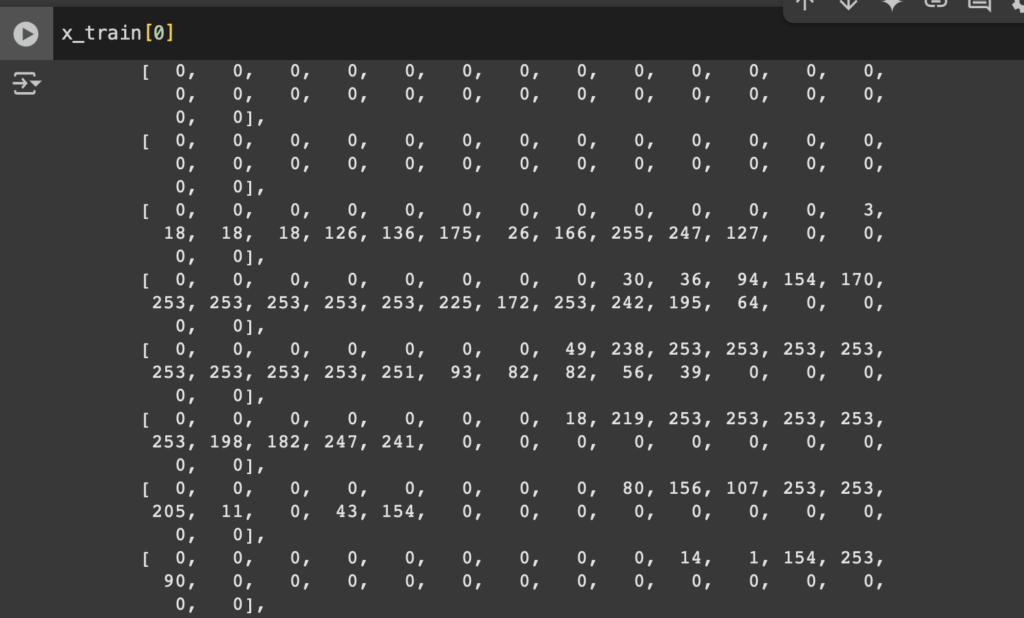
Las imágenes en MNIST tienen píxeles con valores entre 0 y 255 (escala de grises).
Dividir entre 255.0 normaliza los valores al rango [0, 1]
Pasamos de esto:
A esto:
Aplanemos las capas
Las imágenes en MNIST tienen forma (28, 28), es decir, una matriz de 28×28 píxeles. Las redes neuronales densas (Dense) esperan vectores como entrada, no matrices. Debemos transformar las imágenes en vectores. 28×28=784.
Ejecutaremos esta línea de código
x_train = x_train.reshape(-1, 784)
x_test = x_test.reshape(-1, 784)El dataset se transforma de la siguiente manera:
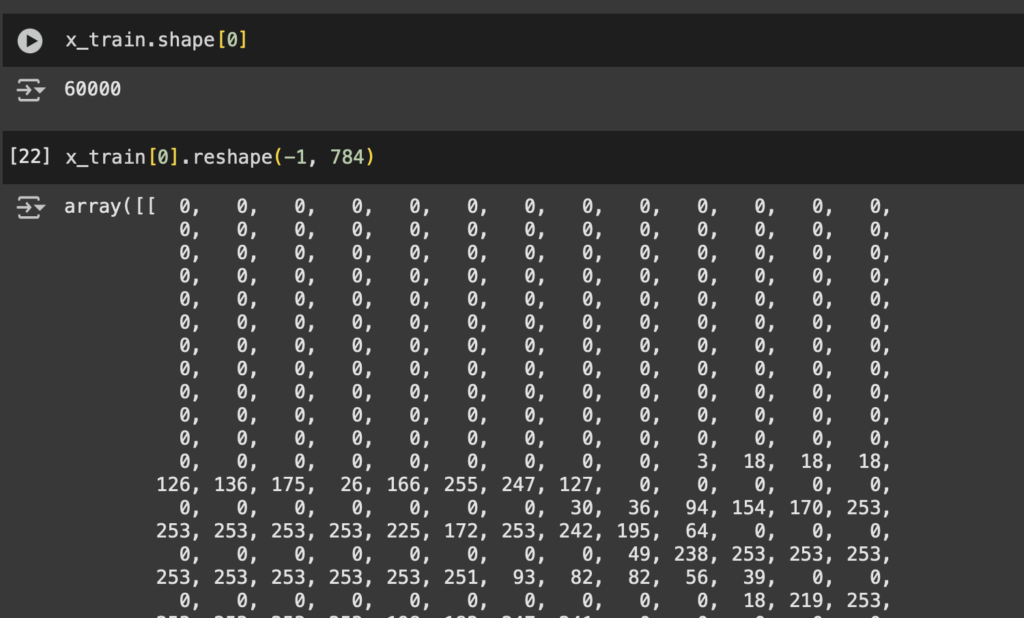
¿Es necesario siempre aplanar los datos? No, esto lo hacemos porque usaremos una red de tipo densa, si quisiéramos usar redes neuronales convolucionales (CNN) en lugar de una red densa, no necesitaríamos aplanar las imágenes. En su lugar, mantendríamos el formato (28,28,1).
Definamos nuestras capas
Importaremos el modelo secuencial y las capas densas de Tensorflow
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import DenseObtendremos la estrategia (relacionado al hardware)
strategy = tf.distribute.get_strategy()Y ahora podemos definir nuestra red neuronal, teniendo en cuenta nuestro optimizador, la función de perdida y métricas
with strategy.scope():
model = Sequential([
Dense(512, activation='relu', input_shape=(784,)),
Dense(256, activation='relu'),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])Podemos ver el detalle de nuestra red neuronal con el comando
model.summary()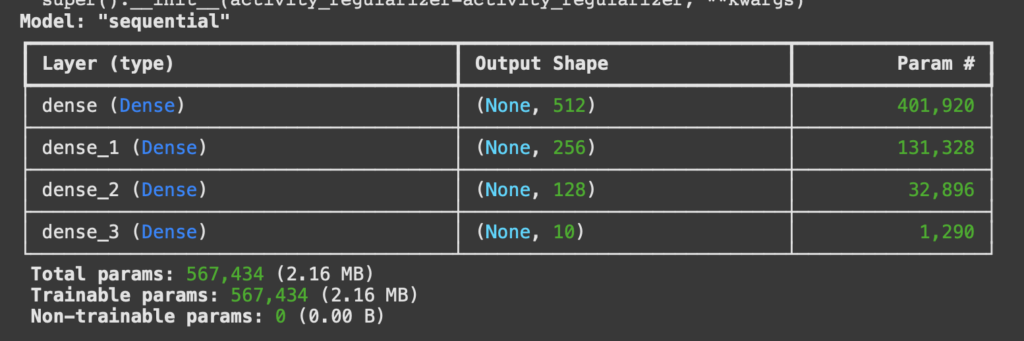
Entrenemos el modelo
Acá definimos cuantas épocas utilizaremos y de cuanto será el lote de entrenamiento.
history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_data=(x_test, y_test))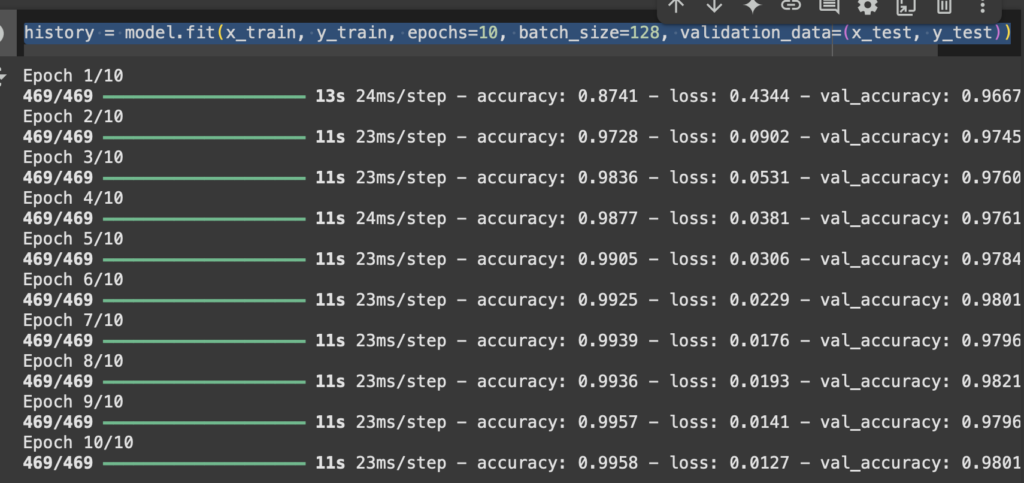
Evaluemos el modelo
Ahora evaluaremos el modelo con nuestro conjunto de validación
test_loss, test_acc = model.evaluate(x_test, y_test)Tenemos un resultado de 97% de exactitud, felicitaciones!