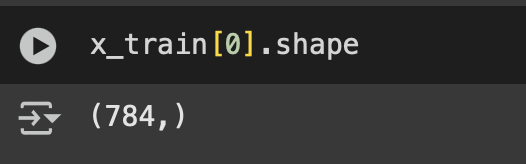
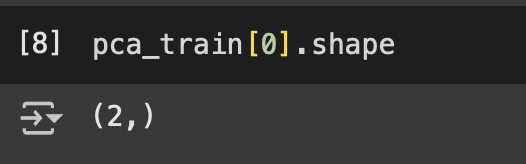
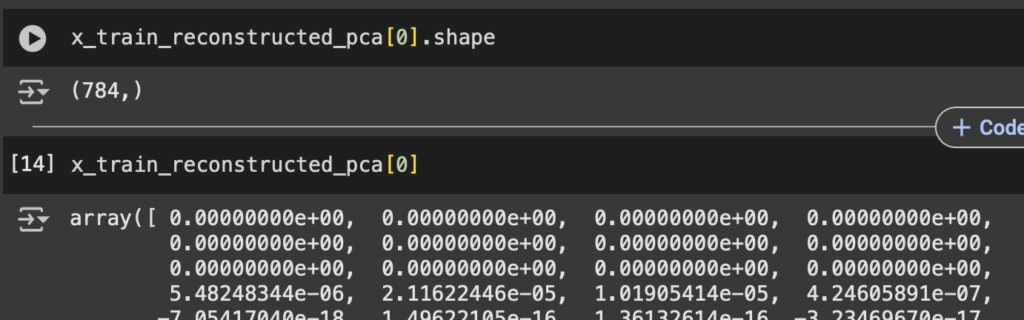
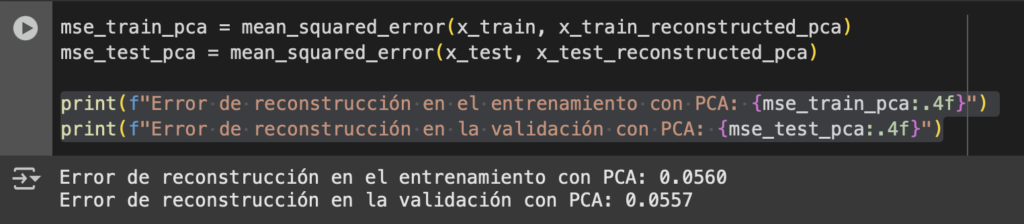
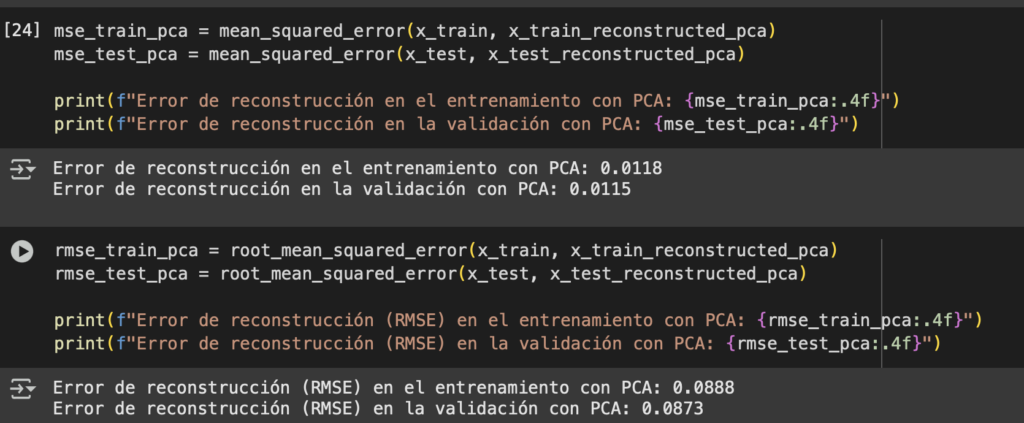
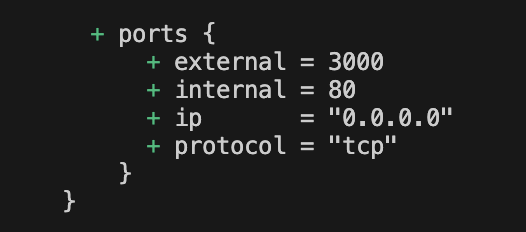
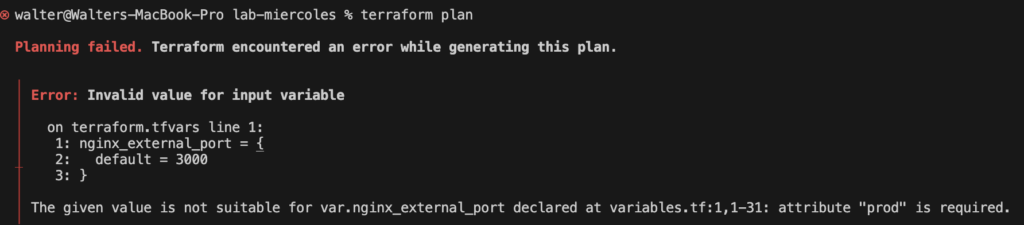
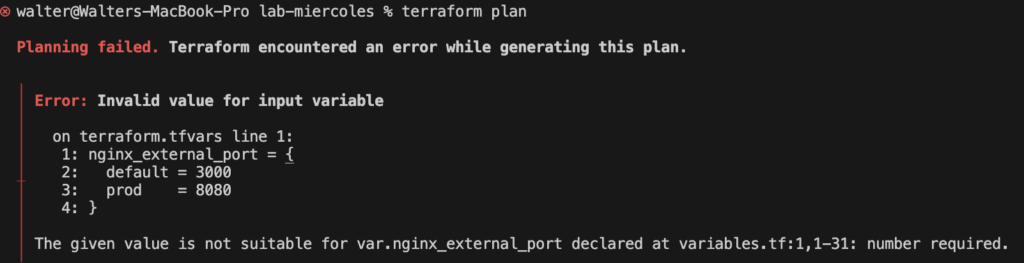
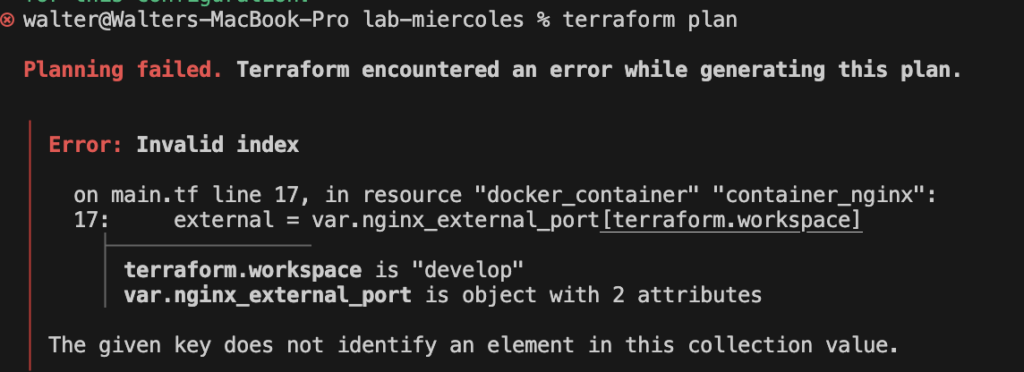
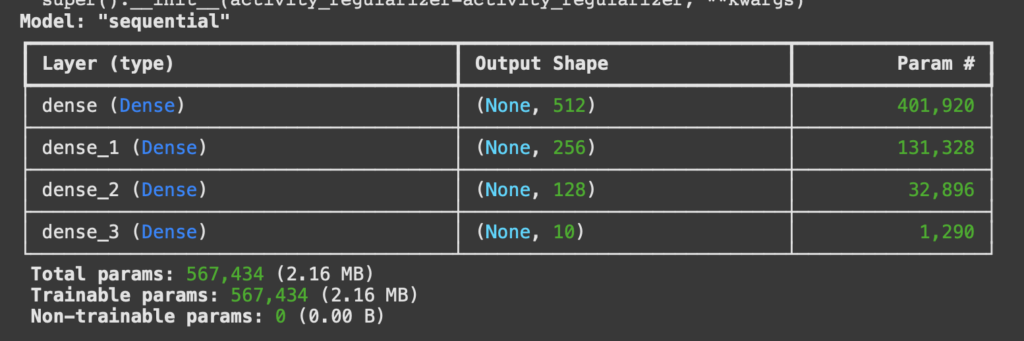
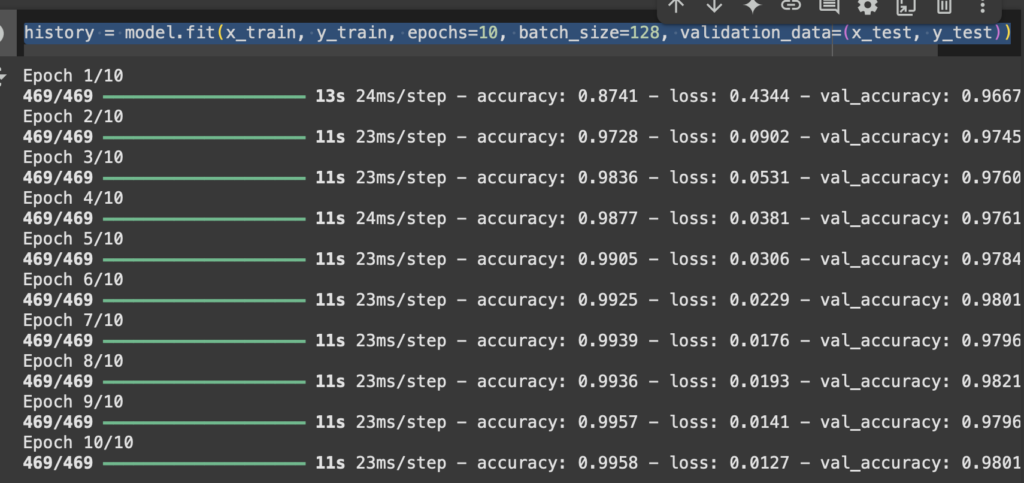
Hemos hablado antes de Terraform y sus ventajas para poder desplegar diferentes recursos. Así como configuración de variables y de entornos de despliegue.
Ahora solo debemos tener un diagrama para guiarnos y que mejor lugar que el propio aws para poder encontrarlo.
Elegí la arquitectura de ejemplo de Simple File Manager for Amazon EFS
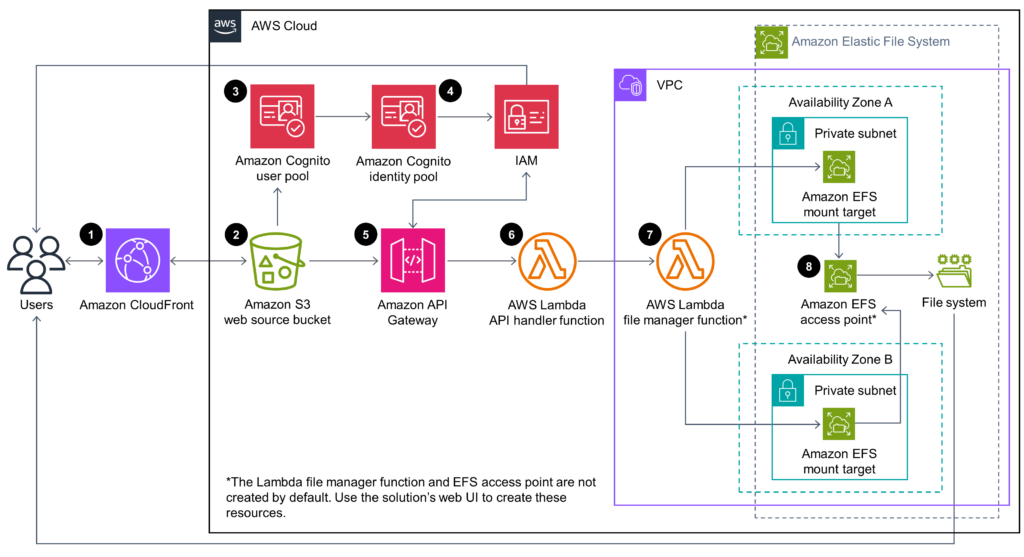
Hoy nos enfocaremos en los siguientes componentes:
- Amazon S3 web source bucket
- Amazon CloudFront
- Amazon Cognito user pool
¿Dónde comenzamos?
El primer paso es instalar e inicializar el proveedor de AWS para Terraform en nuestro main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}Y su configuración, en mi caso utilizaré us-east-2
provider "aws" {
region = "us-east-2"
}Para poder desplegar esta arquitectura es necesario tener el CLI de AWS en el equipo que ejecutará el plan de terraform, además de la configuración de permisos necesaria para que esté vinculado a nuestra cuenta.
S3 Bucket
Debido a que CloudFront recibe parámetros de S3 este será el primer recurso que crearemos.
Para mantener organizado el proyecto crearé un archivo por cada recurso y ahí colocaré todas las configuraciones adicionales, en este caso s3.tf
resource "aws_s3_bucket" "web_bucket" {
bucket = "web-source-bucket"
tags = {
Name = "WebSourceBucket"
}
}Debemos permitir el acceso público a este bucket, el recurso se llama aws_s3_bucket_public_access_block y necesita el id del bucket que hemos declarado, podemos utilizar propiedades de nuestros recursos accediendo a RECURSO.NOMBRE_RECURSO.PROPIEDAD
resource "aws_s3_bucket_public_access_block" "block" {
bucket = aws_s3_bucket.web_bucket.id
block_public_acls = false
block_public_policy = false
ignore_public_acls = false
restrict_public_buckets = false
}Y como última configuración la política de lectura pública
resource "aws_s3_bucket_policy" "public_read" {
bucket = aws_s3_bucket.web_bucket.id
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Sid = "PublicReadGetObject",
Effect = "Allow",
Principal = "*",
Action = ["s3:GetObject"],
Resource = "${aws_s3_bucket.web_bucket.arn}/*"
}
]
})
}CloudFront
La configuración de CloudFront es un poco más extensa de lo que hemos visto hasta ahora, utilicemos el archivo cloudfront.tf
resource "aws_cloudfront_distribution" "cdn" {
origin {
domain_name = aws_s3_bucket.web_bucket.bucket_regional_domain_name
origin_id = "s3Origin"
s3_origin_config {
origin_access_identity = ""
}
}
enabled = true
is_ipv6_enabled = true
default_root_object = "index.html"
default_cache_behavior {
allowed_methods = ["GET", "HEAD"]
cached_methods = ["GET", "HEAD"]
target_origin_id = "s3Origin"
viewer_protocol_policy = "redirect-to-https"
forwarded_values {
query_string = false
cookies {
forward = "none"
}
}
}
restrictions {
geo_restriction {
restriction_type = "none"
}
}
viewer_certificate {
cloudfront_default_certificate = true
}
comment = "LeoCorp"
tags = {
Name = "CloudFrontWebCDN"
}
}Cognito User Pool
resource "aws_cognito_user_pool" "user_pool" {
name = "leocorp"
password_policy {
minimum_length = 8
require_uppercase = true
require_lowercase = true
require_numbers = true
require_symbols = false
}
auto_verified_attributes = ["email"]
alias_attributes = ["email"]
}¿Qué sigue?
Es recomendable tener un archivo outputs.tf el cual muestre información importante para poder identificar los recursos que han sido creados, es común que estos valores se utilicen en posteriores pasos en un pipeline y podemos acceder a ellos a través del entorno.
outputs.tf
output "bucket_name" {
value = aws_s3_bucket.web_bucket.bucket
}
output "cloudfront_domain" {
value = aws_cloudfront_distribution.cdn.domain_name
}
output "cognito_user_pool_id" {
value = aws_cognito_user_pool.user_pool.id
}Pasos próximos
No hemos terminado, de momento nuestro plan puede generar recursos pero debemos considerar el uso de variables.
Ten en cuenta que nuestro S3 necesita un index.html para poder mostrar esta información. Esto también podemos automatizarlo en un pipeline.
Realizaremos estas mejoras en la segunda entrega de esta serie 😀